





Az MI alkalmazása uralja az online közösségi média platformok világát, amelyek korunk egyik legmeghatározóbb fórumai a véleménynyilvánítás szabadságának és egyúttal legnagyobb potenciális fenyegetői is e tárgyalt alapjognak. A véleményszabadsághoz tartozik mind az információszerzés és -közlés joga, amelyek a demokratikus közvélemény biztosítása által tartják fenn a társadalmi kohéziót. Az olyan óriásplatformok pedig, mint a Google, Facebook, YouTube, felhasználók milliói számára az elsődleges informálódási források és önkifejezési közegek, emiatt a szólás- és információs szabadságra jelentős befolyással bírnak ezek a magánkézben lévő oldalak, amelyeket emiatt „kvázi közszférának” is nevezhetünk.
Az egyik általános problémakör az „óriások dominanciája” összefoglaló névvel írható körül, ugyanis az állami és a magánszektor jelentőségének, illetve viszonyának értékelését a szólásszabadság vizsgálatánál nem lehet figyelmen kívül hagyni. Mára egyértelművé vált, mondhatni alapvetése a tárgyalt viszonyoknak, hogy a magánszektorba tartozó óriás online platform szolgáltató cégek jogérvényesítési, illetve jogalkalmazói, sőt, esetenként jogalkotói feladatokat látnak el. A platform belső szabályzata, amelyhez a tartalommoderálást végző mesterséges intelligencia is kötött, felhasználók millióinak a magatartását befolyásolja, jóval több emberét, mint a legtöbb állam önálló lakossága. Ez a szólásszabadságra vetítve azt is jelenti, hogy e jogok érvényesülése a magánszektor kezében van az online teret illetően.
A gyűlöletbeszéd mindig is a társadalmi élet velejárója volt, azonban az online tér ezt a jelenséget felgyorsítja, ezáltal jóval nagyobb mennyiségű ilyen beszéd keletkezik, valamint a klasszikus közéleti színterekkel (sajtó, nyilvános előadások) ellentétben, az internet által a befogadókat a gyűlöletbeszéd egészen „hazáig követi”, ezzel potenciálisan nagyobb veszélyt jelentve a gyűlöletnek kitett csoportok tagjaira.
A Meta (korábban Facebook) vállalat jelentése alapján 2023-ban október elejéig átlagosan 18 millió esetben járt el gyűlöletbeszédnek ítélt tartalommal szemben, ennek 89%-át önállóan kezdeményezte, 11%-át pedig felhasználói bejelentés alapján vizsgálta. Az önálló tartalommoderálás jelentőségét egyértelműen tükrözi az is, hogy alkalmazásának kezdete óta a felhasználói bejelentés alapján induló (77%) és önálló eljárások (23%) aránya a 2018-ban mértekhez képest az imént ismertetett adatok szerint megfordult.
A gyűlöletbeszéd korlátozása leginkább a nem egységes fogalmi meghatározás miatt problémás az online térben.Ahogy a nemzetközi jogban, úgy a magyar jogrendszerben sem találunk egyértelmű definíciót és kritériumrendszert ahhoz, hogy bizonyossággal eldönthető legyen a szólásszabadság és gyűlöletbeszéd között húzódó határ. Az egyik ilyen dilemma például, hogy szükséges-e a clear and present danger doktrínája szerinti közvetlenül fenyegető veszély a megtámadott társadalmi csoport tekintetében, avagy elegendő-e a gyűlöletkeltésre való alkalmasság a korlátozhatóság megállapításához.
A Polgári és Politikai Jogok Nemzetközi Egyezségokmánya alapján különböző súlyú gyűlöletbeszéd-kategóriákat ismerünk. A 20. cikk 2. bekezdése szerint az államoknak “[t]örvényben kell megtiltani a nemzeti, faji vagy vallási gyűlölet bármilyen hirdetését, amely megkülönböztetésre, ellenségeskedésre vagy erőszakra izgat.”. Ez a súlyos gyűlöletbeszéd, azonban a 19. cikk alapján az államok megtilthatnak másfajta gyűlöletbeszédet is, például a diszkrimináció vezérelte fenyegetést, a zaklatást. A harmadik kategóriába pedig az úgynevezett lawful hate speech, azaz megengedett gyűlöletbeszéd tartozik, amely az államok részéről kritikus jogi reakciót igényel, ilyenek például a diszkrimináció egyes formái vagy az intolerancia, illetve az olyan beszédek, amelyek bár megengedettek, de mégis indokolatlanul sértőek, bántóak vagy támadóak.
Következtetésképp elmondható, hogy a gyűlöletbeszéd egységes meghatározásának hiányából fakadóan a mesterséges intelligencia számára az egyes kategóriák felismerését megtanítani problémás. A következőkben tekintsük át az MI alkalmazásának potenciális veszélyeit a gyűlöletbeszéd elleni fellépést illetően.
A mesterséges intelligencia által végzett tartalommoderálás értelemszerűen kétféle hátrányos kimenetelt eredményezhet. Az egyik az úgynevezett over-removal vagy over-blocking, azaz amikor az MI legális tartalmakat is gyűlöletbeszédnek értékel és emiatt eltávolítja vagy már azok feltöltését is korlátozza. Ennek a jelenségnek különösen kitettek a kisebbségi, szélsőséges csoportok, hiszen az általuk használt kifejezések (például: „meleg”, „queer”) megjelenhetnek gyűlöletbeszédben is, ezért azok elhatárolása a védett beszédtől nehézkes feladat az algoritmus számára. A kisebbségi csoportok által használt kifejezéseken túl vannak még egyéb, nem gyűlöletbeszéd kategóriák is, amelyek felismerése komoly kihívás a mesterséges intelligencia számára. Ilyenek az azonos alakú kifejezések, a vulgáris beszéd, valamint az úgynevezett counter speech, amikor a gyűlöletbeszédnek minősülő tartalomra reagáló felhasználó éppen annak negatív hatása ellen lép fel, továbbá a védett körön kívülre (például tárgyakra) irányuló gyűlöletbeszéd is ide tartozik.
A Meta (Facebook) jelentése alapján 2022-ben megközelítőleg 237 ezer hibásan eltávolított tartalom került vissza a platform felületére, ennek mindössze 3%-a az, amelyet a vállalaton belüli ellenőrzés észlelt, a maradék 230 ezer esetben felhasználói fellebbezés eredményeként került újraértékelésre az alaptalanul eltávolított közlés. Jelenlegi adatok alapján 2023 októberéig közel 7 millió esetben állítottak vissza hibásan eltávolított tartalmat, ebből 6 millió (86%) esetben belső ellenőrzési mechanizmus eredményeként és csupán 1 millió alkalommal felhasználói kezdeményezés útján. Ez arra enged következtetni, hogy a belső felülvizsgálati mechanizmus fejlődése előnyös irányba mutat.
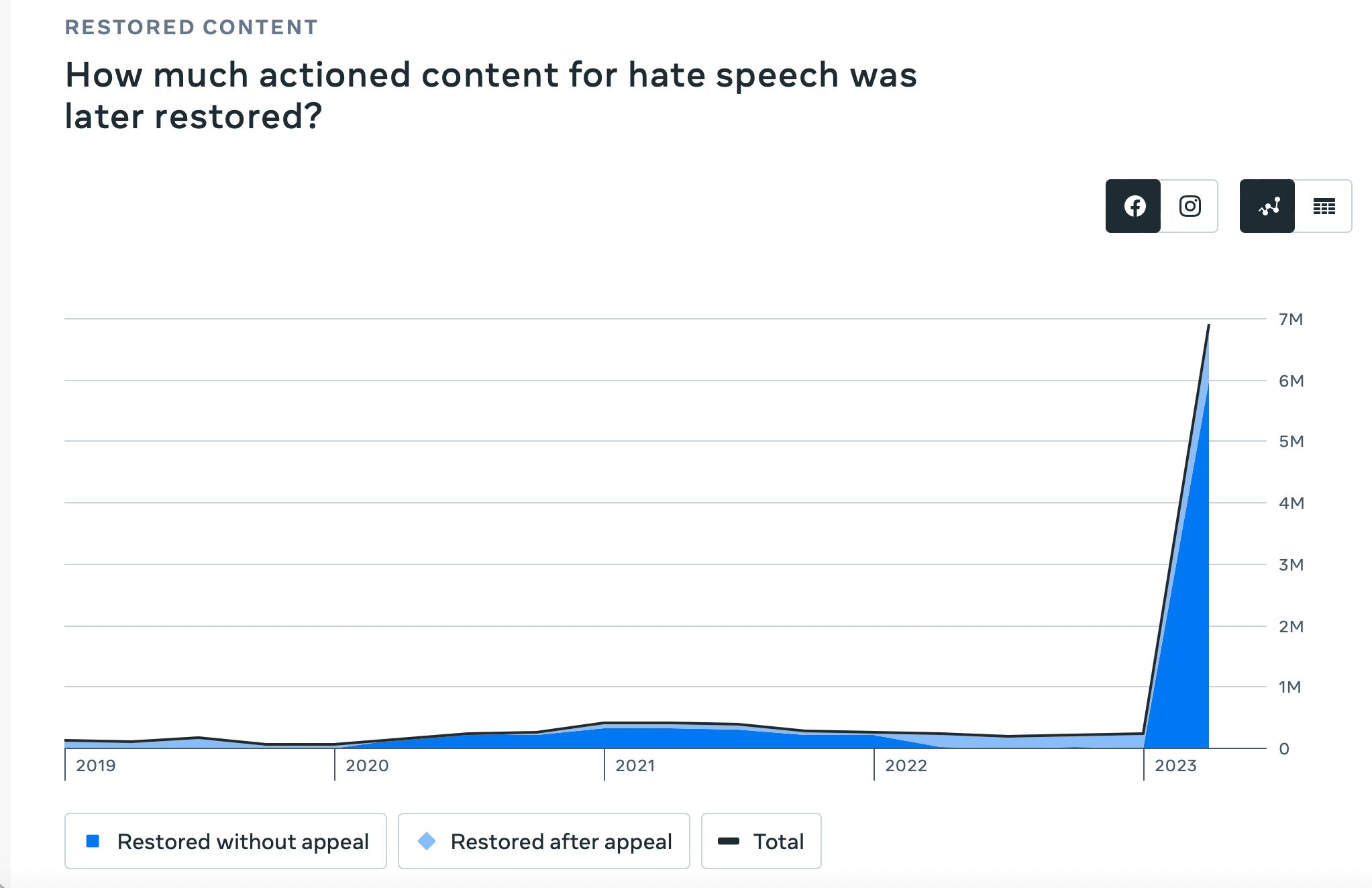 Forrás: Meta Transparency Center
Forrás: Meta Transparency Center
A másik problémás következmény pedig, amikor a mesterséges intelligencia nem képes felismerni és eltávolítani a valóban jogsértő tartalmakat. Az egyensúlyt azért nehéz megalkotni, mert a szigorúbb MI-k, mint például a Google Jigsaw Perspective API nevű eszköze, az over-removal hibáját követik el, míg a megengedőbb szoftver, például a HateCheck összehasonlításában a SwiftNinja, nem képes a valóban jogellenes tartalmak kiszűrésére. Ha a moderálás túl szigorú, akkor a kisebbségi csoportok véleménye is eltávolításra kerül, ha túl kevés, akkor az illegális tartalmak is kicsúsznak a mesterséges intelligencia hálóján.
Könnyen belátható, hogy mindkét problémakör az értelmezés nehézségéből, az ahhoz szükséges kifinomultság és komplex kulturális, illetve nyelvismeret hiányából fakad. Számos tanulmány bizonyítja, hogy a mesterséges intelligencia még nem képes biztossággal felismerni a kulturális, kontextuális nüanszokat, amelyektől egy-egy közlés szólásszabadságot sértő mivolta függ. A Meta (Facebook) 2022-es első negyedévi jelentésében szintén elismeri, hogy komoly feladat a tartalommoderálást végző algoritmust megtanítani a beszédek kontextusban való értelmezésére,márpedig enélkül könnyen előfordulhat, hogy az MI eltávolít valójában védett tartalmat, avagy nem veszi észre az implikált gyűlöletbeszédet.
Az egyik leggyakoribb példája a mesterséges intelligencia értelmezési korlátainak az afroamerikai angol (African American English (AAE)) nyelvezete, amellyel összefüggésben megfigyelték, hogy az e körbe tartozó tartalmakon tanított algoritmusok kétszer nagyobb eséllyel minősítenek gyűlöletbeszédnek AAE dialektusban megfogalmazott tartalmakat, ezzel faji alapú diszkriminációt is okozva. A példából az online platformok globalizáltsága folytán adódik az a további következtetés is, hogy külön problémát okozhat egy adott kulturális közegben tanított mesterséges intelligencia eltérő környezetben való használata, gyakran ezzel pont a gyűlöletbeszédnek kitett csoportok közléseit korlátozva.
Az algoritmusbírók kihívása tehát óriási: egyensúlyozni kell a szólásszabadság és gyűlöletbeszéd közötti határon, amely a jogtudomány számára is nagymúltú feladat. Láthattuk, hogy a mesterséges intelligencia képes a tömeges tartalommoderálásra, de a határok észlelése és a kulturális kontextus értelmezése még nehézségeket okoz. A jövőben a technológiai fejlesztések mellett megfelelő jogi keretekre is szükségünk van ahhoz, hogy megvédjük alapvető jogainkat az online térben.

